
When you first understand the concept of SLO’s the very first thing we tend to do is apply SLO’s for every services. It’s fine that we tend to do that but identifying where and why they should be applied is more important. But before I move forward, first let’s understand the concepts of SLO’s.
What exactly are SLO’s in simple terms?
While SLOs and SLAs may appear similar, they serve fundamentally different purposes. SLAs are external commitments made to customers, often with contractual implications, whereas SLOs are internal agreements within the organization typically between product, engineering, and SRE teams.
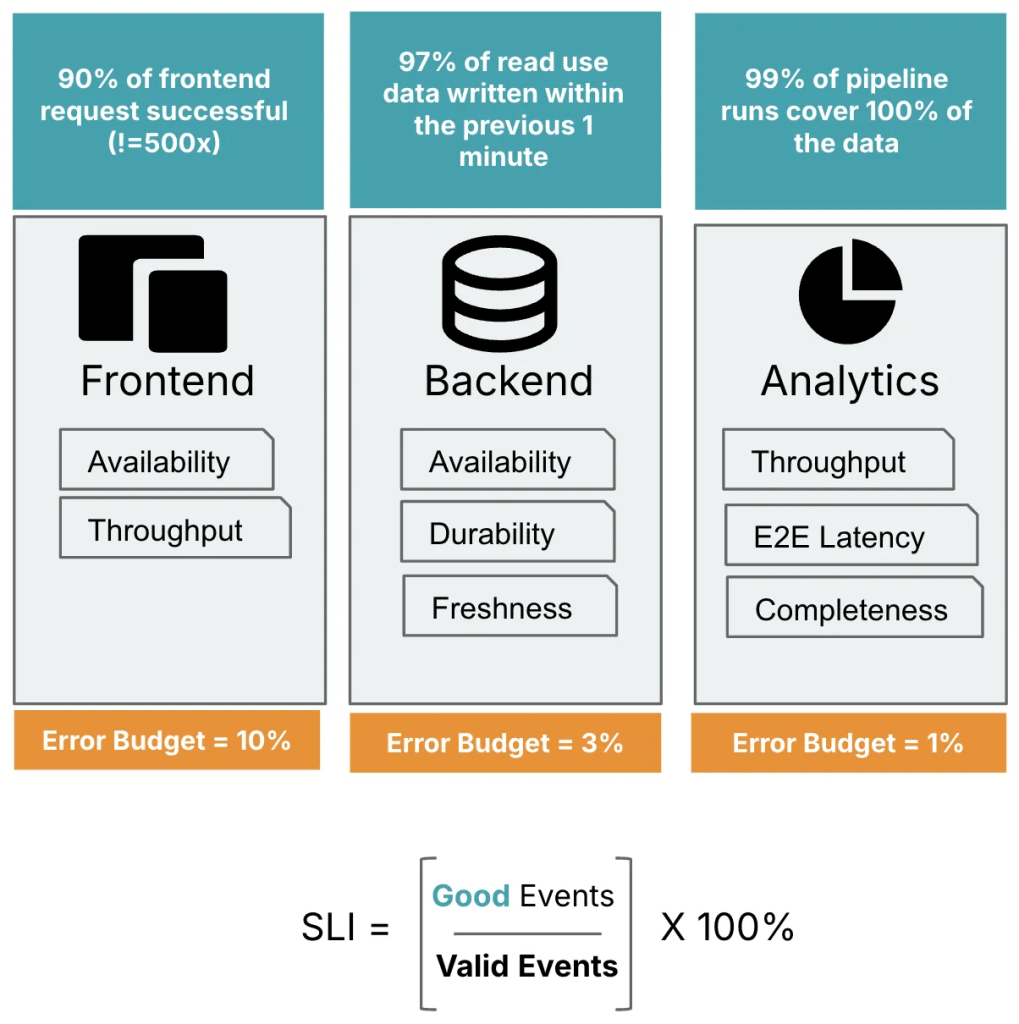
An SLO is essentially a declaration of ownership and accountability which says “I own this service, and I commit that it will respond within 5 seconds 95% of the time.” In essence, SLOs define the expected reliability of a service by setting measurable performance targets that guide operational priorities and engineering focus.
Do all services needs SLO’s
Now that we’ve cleared what SLOs are, it’s important to understand why not every service requires an SLO. I came across an interesting case discussed in a forum, where an SRE team was facing an issues with frequent SLO breaches across multiple services. Although he had the option to lower the reliability targets to avoid breaches, doing so would have compromised the very purpose of setting meaningful SLOs in the first place, they are meant to reflect realistic yet ambitious service expectations, not just passable thresholds.
The SRE team was using SLOTH, an open-source tool designed to generate SLOs based on Prometheus metrics, specifically tailored for services running in Kubernetes environments. SLOTH streamlines the creation of SLO configurations and integrates with monitoring stacks (like Prometheus and Grafana). However, the issue was that the SLOs were applied indiscriminately across all services, without evaluating their business impact or operational significance. As a result, nearly 40% of services were regularly breaching their SLOs, not due to actual performance issues, but because many of those services were not suitable candidates for reliability objectives in the first place.
This case highlights a crucial lesson, applying SLOs universally, without aligning them to the criticality, user impact, or role of the service, can lead to misleading reliability signals and operational noise. It’s essential to be deliberate and strategic about where and how SLOs are implemented to ensure they drive impactful and meaningful outcomes.
Why You Shouldn’t Apply SLOs to Every Service
The reality is that not all services are created equal, and applying SLOs universally can often do more harm than good. Some services are inherently prone to under perform and that can be perfectly acceptable. For instance, in a banking system, an API of a service might have an SLO target of responding within 5 seconds, however during peak traffic hours (e.g., end-of-month transaction spikes), response times may occasionally exceed 10 seconds. This doesn’t necessarily indicate a performance issue, it’s a predictable normal behavior which is acceptable.
This is why it’s critical to carefully select which services warrant SLOs and to define realistic reliability targets. Applying SLOs to every service, especially those that aren’t mission-critical can result in alert fatigue, engineering distraction, and a false sense of unreliability.
This is completely my opinion and I might be wrong but SLOs should be tightly aligned with business outcomes. High-priority candidates typically include services that:
- Handle financial transactions or payments
- Directly impact customer experience
- Are part of a critical user journey (CUJ)
Conducting a CUJ-based analysis helps identify the touch-points that truly matter to end users, allowing teams to focus reliability efforts where they’ll have the most impact. In short, SLOs are not just technical metrics, they are product and business decisions.
Fewer SLOs, Greater Impact
One important point I always emphasize is this -> the fewer SLOs you define, the more impactful they will be.
In the context of observability, one of the most common challenges we face is alert fatigue. When teams are overwhelmed with a high volume of alerts, there’s a natural tendency to ignore them, including the ones that actually matter.
In contrast, when alerts are rare but meaningful, they command attention. This same principle applies to SLOs. By keeping your SLOs focused and limited to high-value, business-critical services, each SLO breach becomes a signal worth investigating, not just more noise. In fact, the more selective you are with where SLOs are applied, the stronger their operational and strategic impact becomes.
In a microservices architecture, where services are highly interconnected, an SLO on a single service can often reflect issues in downstream or upstream dependencies. For example, if Service A has an SLO breach but the root cause lies in Service B (a dependency), that breach still serves as a valuable early warning worth investigating.
To summarize, it’s perfectly fine to have general monitoring and alerts for all services, but SLOs should be reserved for services where reliability truly matters where every breach is taken seriously and leads to action.
And just to add a bit of humor, I sometimes jokingly say SLO stands for “Service Losing Out” when it fails to meet expectations. But in all seriousness, treating SLOs with the right level of gravity is key to running a resilient and efficient system.

Leave a comment